The research portal takes data in three formats: comma-separated values (.csv), JSON, and BioIndex (a custom database in the HuGeAMP framework). In this chapter we will discuss each of the data formats. But first let's look at how the data points can be configured.
There are four fields you need to look at to configure your data sources.
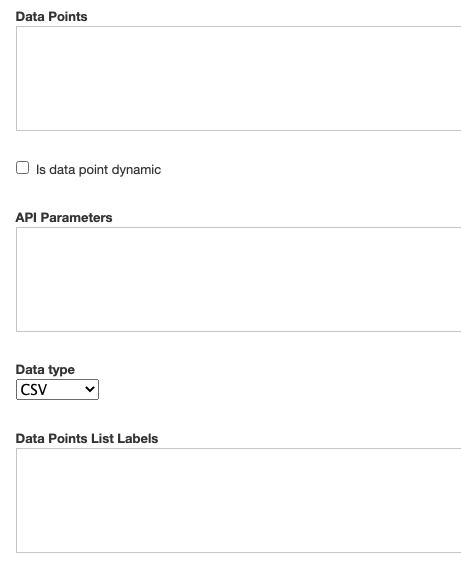
In the Data Points field you may enter:
- the names of the files you upload to your account
- the names of files on remote online sources like DropBox
- APIs that return queries with parameters.
The Data Points field takes multiple data sources separated with commas. Here are some examples:
Example 1: file_name1.csv, file_name2.csv
Example 2: http://apiexample.org/firstapicall/, http://apiexample.org/secondapicall/
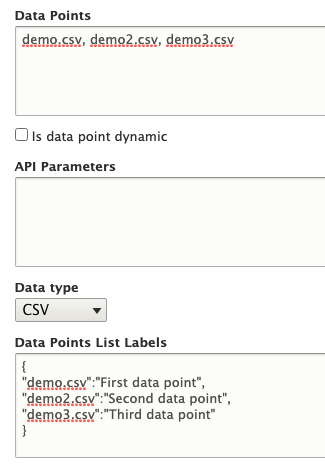
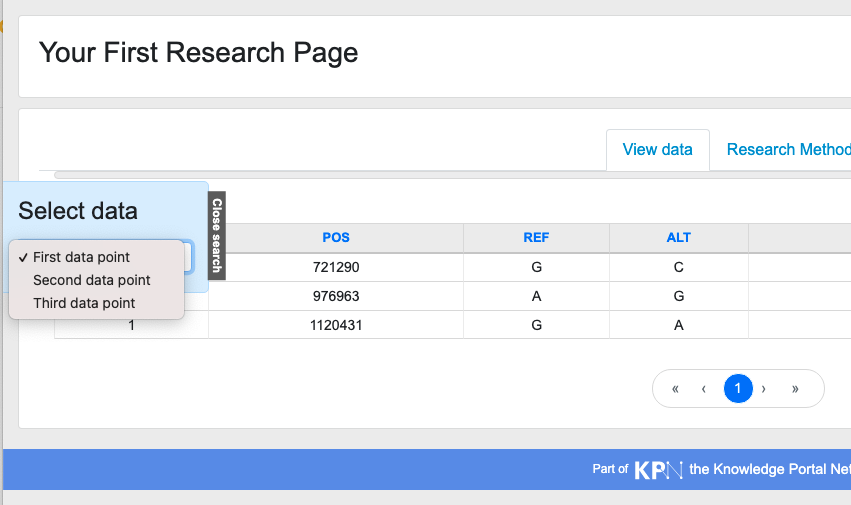
When there is more than one entry in the Data Points field, the research portal will add a data select menu to your research page. To have the menu show up correctly, you will have to add labels for each data point to the 'Data Points List Labels' field. Here is an example of a configuration and its expected outcome on the research portal:
If your data point is a dynamic one, like most common APIs that take parameters for data query, you will need to check the 'Is data point dynamic' check box and specify parameters in the 'API Parameters' field. Here is an example:

This example points to a BioIndex database that the research portal team has set up. It takes three parameters to query data: ancestry, phenotype, and region. API calls are usually private, which requires admins of the API servers to take calls from the IP addresses of the API calling applications. Also, since formatting of the returned data may vary, it can be quite challenging to use without code modification on the research portal development team side. We currently support dynamic data points only for registered users.